Lustre 2.15.4 on RHEL 8.9 and Ubuntu 22.04
Introduction
The main purpose of this post is not to explain what Lustre is, but to give an up-to-date document for installing and configuring the current latest Lustre version (2.15.4) on supported platforms RHEL 8.9 for servers and Ubuntu 22.04 for clients. It can be used as a basic guide for production use but I have not installed or managed Lustre in production and I am not touching any production specific topics in this post.
The reason I wrote this post is because the documentation I found for installing Lustre is usually old. For example, the installation page on wiki mentions RHEL 7 which is not supported anymore. The Lustre 101 introdutory course created by Oak Ridge Leadership Computing Facility is great, but it is also created more than 5 years ago.
I think the installation steps on the installation page on wiki should slightly be modified for RHEL 8.9 for installing servers. In this post, I give my version of installation steps of Lustre servers on RHEL 8.9.
Also, Lustre 2.15.4 client packages for Ubuntu 22.04 does not include a DKMS package. I will compile and build DKMS packages first and install the Lustre client on an Ubuntu 22.04 and test my setup.
Lustre
It is not the main purpose of this post, but if you know nothing about Lustre, I should give a brief introduction for this post to make some sense. If you are familiar with Lustre, you can skip this section.
From its website and from the Introduction to Lustre Architecture document:
Lustre is “an open-source, object-based, distributed, parallel, clustered file system” “designed for maximum performance at massive scale”.
It “supports many requirements of leader-ship class HPC simulation environments”.
Lustre is the most popular file system used in supercomputers. The best supercomputer in Europe at the moment (#5 in TOP500 November 2023) is LUMI and it also uses Lustre.
It is common in HPC environments, but because it can handle very large capacities with high performance, I guess it would not be surprising to see Lustre anywhere large datasets are read or written from a large number of clients.
There are three different servers in Lustre.
- ManaGement Server (MGS): keeps the configuration information for all file system
- MetaData Server (MDS): manages the metadata, ACLs etc. of a file system
- Object Storage Server (OSS): handles the actual data I/O of the files
It means the MGS is shared by all the file systems, whereas a particular MDS or OSS is only for one particular file system. Since the metadata is separated from the actual data, all metadata operations are performed by MDS, whereas actual data operations are performed by OSS.
The storage component (block device, logical volume, ZFS dataset etc.) of these servers are called a target:
- MGS keeps its data on ManaGement Target (MGT)
- MDS keeps its data on MetaData Target(s) (MDT)
- OSS keeps its data on Object Storage Target(s) (OST)
The format of the targets, called object storage device (OSD), can be LDISKFS (which is derived from ext4) or ZFS. Thus, for example, OSS can store the file data on a ZFS dataset.
Because of separation of roles, the hardware requirement for the servers are different:
- MGS is infrequently accessed, performance not critical, data is important (mirror, RAID-1). It requires less than 1 GB storage (maybe even less than 100MB).
- MDS is frequently accessed like a database, small I/O, data is critical (striped mirrors, RAID-10). It requires 1-2% of the total file system capacity.
- OSS is usually I/O bound. Typically one OSS has 2-8 OSTs. RAID6 (8+2) is a typical choice.
Lustre on its own does not provide any redundancy. The targets have to provide redundancy on their own using a hardware or a software solution. For high availability or redundancy of the servers, cluster pairs (failover) are required.
A very small deployment with one file system would consists of:
- one node for both MGS (one MGT) and MDS (one MDT)
- one node for OSS (one or more OSTs)
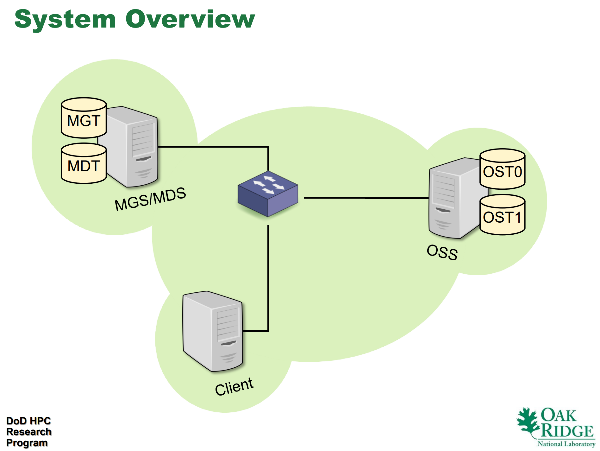
System Overview (src: Lustre 101)
A more typical deployment would consist of:
- one MGS (for one or many file systems)
- a few MDS (one for each file system, it is possible to use more than one per file system if required)
- many OSS (more than one OSS for each file system)
For example, each Lustre file system on LUMI supercomputer has 1 MDS and 32 OSTs on Main storage - LUMI-P. Each file system is 20 PB.
An extra MDS for a file system is only required to scale metadata capacity and performance.
Lustre servers are not managed like Linux services. They are started by mounting a target and stopped by unmounting the target. The type of the target determines the service started.
The Lustre client is installed on computers to access Lustre file systems. The communication protocol between the client and the servers is Lustre Network protocol (LNet). When a client wants to access a file, it first connects to the MDS. MDS provides information about how the file is stored. Client calculates which OST’s should be contacted for required operation and directly connects to these OSTs.
Similar to striped RAID/ZFS, a file in Lustre is striped across OSTs, depending on stripe_count and stripe_size options. These can be set individually for each file (or the default values are inherited). Each file is striped to stripe_count OSTs and each part in OST has stripe_size bytes.
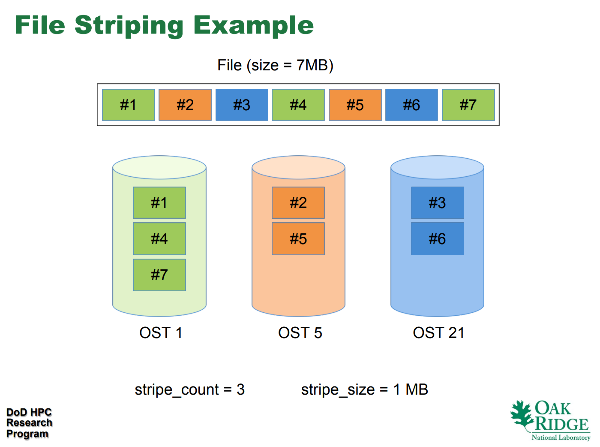
File Striping Example (src: Lustre 101)
Install Lustre servers
Lustre 2.15.4 supports only RHEL 8.9 as a server.
If you do not already have access to a RHEL subscription, Red Hat provides a no-cost RHEL individual developer subscription.
I have installed RHEL 8.9 with standard Server without GUI software set and after the install I did an update with dnf update.
Lustre supports LDISKFS (which is based on ext4) and ZFS. LDISKFS support requires a Lustre patched kernel, whereas ZFS support can be added with modules (without patching the kernel). It is possible to install Lustre supporting both or only one of them.
Obviously both works fine but they have different cons.
I first installed Lustre with LDISKFS support only. It is not difficult (probably easier than ZFS support), and it might be easier to work with if you are not used to ZFS. However, it requires a patched kernel. So, you cannot freely update the kernel.
ZFS support does not require a patched kernel, and ZFS has more features. The problem is, Lustre installation page describes installing ZFS as a DKMS package. This makes sense, so the kernel can be updated. However, RHEL 8.9 does not by default support DKMS. So,
epel-releasehas to be installed separately. I think it is also possible to install ZFS as kmod but it is not mentioned in the installation, so I am not sure if it is supported or not.
My understanding is Lustre with ZFS has some performance issues on certain cases. However, there are also different benefits due to the features of ZFS.
I decided to continue using ZFS, so I show the Lustre servers installation steps below supporting only ZFS. If you want to install LDISKFS support, it is not difficult, just skip the ZFS installation steps, and install the Lustre patched kernel and LDISKFS packages as described in the installation page on wiki.
Prepare
This information is mostly taken from Operating System Configuration Guidelines For Lustre.
Static IPv4: Lustre servers require a static IPv4 (and IPv6 is not supported). If using DHCP, setup a static IP configuration (for example with
nmcli) and reboot to be sure the IP configuration is working fine. Make sure the hostname resolves to the IP address, not to loopback address (127.0.0.1). If required, add the hostname with the static IP to/etc/hosts.NTP: Not strictly required by Lustre but time synchronization is a must in a cluster, so install NTP. I have installed
chrony.Identity Management: In a cluster, all user and group IDs (UIDs and GIDs) has to be consistent. I am using an LDAP server installed on another server in my home lab and using
sssdwith ldap in the cluster including Lustre servers. For a very simple demonstration, you can just add the same users and groups to all servers and clients with the same UIDs and GIDs.At least for an evaluation, it does not make sense to have firewalld and SELinux. I have disabled both:
$ systemctl disable firewalld
$ systemctl stop firewalld
$ systemctl mask firewalld
and set SELINUX=disabled in /etc/selinux/config and reboot. After reboot, check with sestatus.
$ sestatus
SELinux status: disabled
Use a supported kernel
Lustre recommends to use a supported kernel version. Lustre 2.15.4 supports 4.18.0-513.9.1.el8_9 on RHEL 8.9. At the moment RHEL 8.9 (updated on 11/04/2024) has the following version:
$ uname -r
4.18.0-513.24.1.el8_9.x86_64
If you want, you can go back to supported version but I think it is a very minor difference (4.18.0-513.24.1 vs. 4.18.0-513.9.1) and it should not matter for this post.
In the next step (Install ZFS packages), kernel-devel package will be installed. If you install a different kernel version now, make sure you also install the correct kernel-devel and related (kernel-headers etc.) packages.
Generate a persistent hostid
Not a must for a demonstration, but to protect ZFS zpools to be simultaneously imported on multiple servers, a persistent hostid is required. Simply run gethostid, this will create /etc/hostid if it does not exist.
Install ZFS packages
RHEL does not by default support DKMS. epel-release package is required for that but it is not available from RedHat repositories. Install epel-release from Fedora project:
$ subscription-manager repos --enable codeready-builder-for-rhel-8-$(arch)-rpms
$ dnf install https://dl.fedoraproject.org/pub/epel/epel-release-latest-8.noarch.rpm
Then, add the ZFS repository:
$ dnf install https://zfsonlinux.org/epel/zfs-release-2-3$(rpm --eval "%{dist}").noarch.rpm
Then, install kernel-devel and zfs in DKMS style packages.
$ dnf install kernel-devel
$ dnf install zfs
Lets check if everything is OK by loading the zfs module:
$ modprobe -v zfs
insmod /lib/modules/4.18.0-513.24.1.el8_9.x86_64/extra/spl.ko.xz
insmod /lib/modules/4.18.0-513.24.1.el8_9.x86_64/extra/znvpair.ko.xz
insmod /lib/modules/4.18.0-513.24.1.el8_9.x86_64/extra/zcommon.ko.xz
insmod /lib/modules/4.18.0-513.24.1.el8_9.x86_64/extra/icp.ko.xz
insmod /lib/modules/4.18.0-513.24.1.el8_9.x86_64/extra/zavl.ko.xz
insmod /lib/modules/4.18.0-513.24.1.el8_9.x86_64/extra/zlua.ko.xz
insmod /lib/modules/4.18.0-513.24.1.el8_9.x86_64/extra/zzstd.ko.xz
insmod /lib/modules/4.18.0-513.24.1.el8_9.x86_64/extra/zunicode.ko.xz
insmod /lib/modules/4.18.0-513.24.1.el8_9.x86_64/extra/zfs.ko.xz
$ dmesg
...
[ 2338.170674] ZFS: Loaded module v2.1.15-1, ZFS pool version 5000, ZFS filesystem version 5
ZFS seems to be working.
Install Lustre servers with ZFS support
First, add the lustre.repo configuration:
$ cat /etc/yum.repos.d/lustre.repo
[lustre-server]
name=lustre-server
baseurl=https://downloads.whamcloud.com/public/lustre/lustre-2.15.4/el8.9/server/
exclude=*debuginfo*
enabled=0
gpgcheck=0
Then, install the packages:
$ dnf --enablerepo=lustre-server install lustre-dkms lustre-osd-zfs-mount lustre
The installed packages are:
lustre-dkmslustre-osd-zfs-mount: Lustre ZFS support for mount and mkfslustre: user space tools and files for Lustre
The Installing the Lustre Software page also lists lustre-resource-agents package to be installed. This package depends on resource-agents package which is not available in my RHEL 8.9 installation. I do not know if this is an error or this is changed with RHEL 8.9 or resource-agents is related to HA installations and my subscriptions might not be covering this. Anyway, it should not matter for the purpose of this post.
Check installation
Lets check if everything is OK by loading the lustre modules:
$ modprobe -v lustre
insmod /lib/modules/4.18.0-513.24.1.el8_9.x86_64/kernel/net/sunrpc/sunrpc.ko.xz
insmod /lib/modules/4.18.0-513.24.1.el8_9.x86_64/extra/libcfs.ko.xz
insmod /lib/modules/4.18.0-513.24.1.el8_9.x86_64/extra/lnet.ko.xz
insmod /lib/modules/4.18.0-513.24.1.el8_9.x86_64/extra/obdclass.ko.xz
insmod /lib/modules/4.18.0-513.24.1.el8_9.x86_64/extra/ptlrpc.ko.xz
insmod /lib/modules/4.18.0-513.24.1.el8_9.x86_64/extra/fld.ko.xz
insmod /lib/modules/4.18.0-513.24.1.el8_9.x86_64/extra/fid.ko.xz
insmod /lib/modules/4.18.0-513.24.1.el8_9.x86_64/extra/osc.ko.xz
insmod /lib/modules/4.18.0-513.24.1.el8_9.x86_64/extra/lov.ko.xz
insmod /lib/modules/4.18.0-513.24.1.el8_9.x86_64/extra/mdc.ko.xz
insmod /lib/modules/4.18.0-513.24.1.el8_9.x86_64/extra/lmv.ko.xz
insmod /lib/modules/4.18.0-513.24.1.el8_9.x86_64/extra/lustre.ko.xz
$ dmesg
[ 3228.388487] Lustre: Lustre: Build Version: 2.15.4
[ 3228.470845] LNet: Added LNI 192.168.54.3@tcp [8/256/0/180]
[ 3228.470999] LNet: Accept secure, port 988
Lustre modules seems to be working.
At this point Lustre servers with ZFS support is ready to be used.
Lustre modules can be unloaded with (you do not have to do this):
$ lustre_rmmod
Configure Lustre file systems
Just for a quick demo, I will create two file systems, and Lustre will consist of:
- one MGS (one MGT, 1 GB)
- one MDS (one MDT, 2 GB) per file system (2 MDT in total)
- four OSS (four OST, 4x 16 GB) per file system (8 OST in total)
The file systems are named users and projects.
All servers in this demo will run on the same host, called lfs. Thus, clients can mount the file systems as lfs:/users and lfs:/projects since lfs is the name of MGS node.
I have an iSCSI target which is connected to lfs and the block device is /dev/sdb. I will create a volume group on /dev/sdb and create multiple logical volumes to be used as Lustre targets.
Configuring Lustre file systems is not difficult but a number of commands have to be executed (think about creating each target, mounting them etc.). To simplify this, I wrote lustre-utils.sh which is available on lustre-utils.sh@github. It is a simple tool that executes multiple commands to create and remove Lustre file systems and starting and stopping the corresponding Lustre servers.
Below is all the commands required, skipping the outputs except the last one:
$ sudo ./lustre-utils.sh create_vg lustre /dev/sdb
$ sudo ./lustre-utils.sh create_mgt zfs
$ sudo ./lustre-utils.sh create_fs users zfs 2 1 zfs 16 4
$ sudo ./lustre-utils.sh create_fs projects zfs 2 1 zfs 16 4
$ sudo ./lustre-utils.sh start_mgs
$ sudo ./lustre-utils.sh start_fs users
$ sudo ./lustre-utils.sh start_fs projects
$ sudo ./lustre-utils.sh status
VG name is lustre
MGT (zfs) is OK, MGS is running
filesystem: projects
mdt0 (zfs) is OK, MDS is running
ost0 (zfs) is OK, OSS is running
ost1 (zfs) is OK, OSS is running
ost2 (zfs) is OK, OSS is running
ost3 (zfs) is OK, OSS is running
filesystem: users
mdt0 (zfs) is OK, MDS is running
ost0 (zfs) is OK, OSS is running
ost1 (zfs) is OK, OSS is running
ost2 (zfs) is OK, OSS is running
ost3 (zfs) is OK, OSS is running
These commands in the same order:
- create a volume group named
lustreon/dev/sdb - create MGT using ZFS backend
- create MDT0, OST0, OST1, OST2 and OST3 for file system
usersusing ZFS backend - create MDT0, OST0, OST1, OST2 and OST3 for file system
projectsusing ZFS backend - start MGS by mounting MGT
- start MDS and OSS of file system
usersby mounting its MDT0 and OSTs - start MDS and OSS of file system
projectsby mounting its MDT0 and OSTs - and finally display the status
The targets are created by running lvcreate to create the logical volume and mkfs.lustre to create the actual target (which, for ZFS, implicitly calls zpool and zfs to create ZFS pool and dataset). The targets are mounted by mount -t lustre. You can see all the parameters in lustre-utils.sh.
For completeness, lets check logical volumes with lvs:
$ sudo lvs lustre
LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert
mgt lustre -wi-ao---- 1.00g
projects_mdt0 lustre -wi-ao---- 2.00g
projects_ost0 lustre -wi-ao---- 16.00g
projects_ost1 lustre -wi-ao---- 16.00g
projects_ost2 lustre -wi-ao---- 16.00g
projects_ost3 lustre -wi-ao---- 16.00g
users_mdt0 lustre -wi-ao---- 2.00g
users_ost0 lustre -wi-ao---- 16.00g
users_ost1 lustre -wi-ao---- 16.00g
users_ost2 lustre -wi-ao---- 16.00g
users_ost3 lustre -wi-ao---- 16.00g
ZFS pools with zpool:
$ zpool list
NAME SIZE ALLOC FREE CKPOINT EXPANDSZ FRAG CAP DEDUP HEALTH ALTROOT
mgt 960M 8.15M 952M - - 0% 0% 1.00x ONLINE -
projects_mdt0 1.88G 8.14M 1.87G - - 0% 0% 1.00x ONLINE -
projects_ost0 15.5G 8.23M 15.5G - - 0% 0% 1.00x ONLINE -
projects_ost1 15.5G 8.21M 15.5G - - 0% 0% 1.00x ONLINE -
projects_ost2 15.5G 8.24M 15.5G - - 0% 0% 1.00x ONLINE -
projects_ost3 15.5G 8.27M 15.5G - - 0% 0% 1.00x ONLINE -
users_mdt0 1.88G 8.12M 1.87G - - 0% 0% 1.00x ONLINE -
users_ost0 15.5G 8.22M 15.5G - - 0% 0% 1.00x ONLINE -
users_ost1 15.5G 8.23M 15.5G - - 0% 0% 1.00x ONLINE -
users_ost2 15.5G 8.24M 15.5G - - 0% 0% 1.00x ONLINE -
users_ost3 15.5G 8.23M 15.5G - - 0% 0% 1.00x ONLINE -
and mounted targets with mount:
$ mount | grep lustre
mgt/lustre on /lustre/mgt type lustre (ro,svname=MGS,nosvc,mgs,osd=osd-zfs)
users_mdt0/lustre on /lustre/users/mdt0 type lustre (ro,svname=users-MDT0000,mgsnode=192.168.54.3@tcp,osd=osd-zfs)
users_ost0/lustre on /lustre/users/ost0 type lustre (ro,svname=users-OST0000,mgsnode=192.168.54.3@tcp,osd=osd-zfs)
users_ost1/lustre on /lustre/users/ost1 type lustre (ro,svname=users-OST0001,mgsnode=192.168.54.3@tcp,osd=osd-zfs)
users_ost2/lustre on /lustre/users/ost2 type lustre (ro,svname=users-OST0002,mgsnode=192.168.54.3@tcp,osd=osd-zfs)
users_ost3/lustre on /lustre/users/ost3 type lustre (ro,svname=users-OST0003,mgsnode=192.168.54.3@tcp,osd=osd-zfs)
projects_mdt0/lustre on /lustre/projects/mdt0 type lustre (ro,svname=projects-MDT0000,mgsnode=192.168.54.3@tcp,osd=osd-zfs)
projects_ost0/lustre on /lustre/projects/ost0 type lustre (ro,svname=projects-OST0000,mgsnode=192.168.54.3@tcp,osd=osd-zfs)
projects_ost1/lustre on /lustre/projects/ost1 type lustre (ro,svname=projects-OST0001,mgsnode=192.168.54.3@tcp,osd=osd-zfs)
projects_ost2/lustre on /lustre/projects/ost2 type lustre (ro,svname=projects-OST0002,mgsnode=192.168.54.3@tcp,osd=osd-zfs)
projects_ost3/lustre on /lustre/projects/ost3 type lustre (ro,svname=projects-OST0003,mgsnode=192.168.54.3@tcp,osd=osd-zfs)
Both file systems are ready to be accessed by the clients.
Install Lustre client
Lustre 2.15.4 supports RHEL 8.9, RHEL 9.3, SLES 15 and Ubuntu 22.04 as a client.
The problem with its Ubuntu support is that the kernel module for Ubuntu 22.04 distributed with Lustre 2.15.4 is built for the kernel version 5.15.0-88. Ubuntu 22.04 shipped with Linux kernel 5.15 (linux-image-generic package is still 5.15), however, at the moment, the version is 5.15.0-102, and it is possible to install and use Linux kernel 6.5 (linux-image-generic-hwe-22.04). So it is not possible to use the Lustre client modules out of the box in either of these.
Another issue is, unlike RHEL and SLES client packages, there is neither a DKMS package for Ubuntu. So the best solution would be to compile the sources and build a DKMS package.
Compile Lustre sources for Ubuntu 22.04 client DKMS packages
The source code of 2.15.4 can be downloaded from its git repository.
To compile the source, I am using an up-to-date Ubuntu 22.04.4 (but still using the 5.15 kernel), and installed the following packages.
$ sudo apt install build-essential libtool pkg-config flex bison libpython3-dev libmount-dev libaio-dev libssl-dev libnl-genl-3-dev libkeyutils-dev libyaml-dev libreadline-dev module-assistant debhelper dpatch libsnmp-dev mpi-default-dev quilt swig
After extracting the source code from the snapshot:
$ sh autogen.sh
$ ./configure --disable-server
$ make dkms-debs
After some time, this generates some deb packages under debs/ directory.
$ ls debs/
lustre_2.15.4-1_amd64.changes lustre-dev_2.15.4-1_amd64.deb
lustre_2.15.4-1.dsc lustre-iokit_2.15.4-1_amd64.deb
lustre_2.15.4-1.tar.gz lustre-source_2.15.4-1_all.deb
lustre-client-modules-dkms_2.15.4-1_amd64.deb lustre-tests_2.15.4-1_amd64.deb
lustre-client-utils_2.15.4-1_amd64.deb
Next, I will install client-modules-dkms and client-utils.
Install Lustre Ubuntu 22.04 client DKMS packages
$ sudo dpkg -i debs/lustre-client-modules-dkms_2.15.4-1_amd64.deb
causes some dependency errors so they are fixed with:
$ sudo apt --fix-broken install
this will start building the Lustre client modules for the current kernel. Finally, install the client-utils package:
$ sudo dpkg -i debs/lustre-client-utils_2.15.4-1_amd64.deb
The Lustre client should be ready. Lets test.
Test
Mounting Lustre filesystems is easy. Before doing that, make sure you have the same user UIDs and group GIDs between the server(s) and client(s), otherwise you will get permission errors.
Lets mount the users file system:
$ sudo mkdir /users
$ sudo mount -t lustre lfs:/users /users
$ sudo dmesg
...
[ 33.139345] Lustre: Lustre: Build Version: 2.15.4
[ 33.190039] LNet: Added LNI 192.168.54.21@tcp [8/256/0/180]
[ 33.190075] LNet: Accept secure, port 988
[ 34.273047] Lustre: Mounted users-client
$ mount | grep lustre
192.168.54.3@tcp:/users on /users type lustre (rw,checksum,flock,nouser_xattr,lruresize,lazystatfs,nouser_fid2path,verbose,encrypt)
The Lustre file system is mounted as expected. Not for measuring performance but a simple test can be initiated with iozone (iozone3 package):
$ cd /users
$ sudo iozone -i0 -i1 -r1m -s1g -f test -+n
gives 1.7 GB/s write, 5 GB/s read speed.
What happens on kernel version 6.5 ?
I wonder what happens if I install linux-image-generic-hwe-22.04 giving kernel version 6.5. I installed it and then DKMS requested to install linux-headers-6.5.0-27-generic which I did and this triggered DKMS compilation. However it resulted with the following:
Error! Bad return status for module build on kernel: 6.5.0-27-generic (x86_64)
Consult /var/lib/dkms/lustre-client-modules/2.15.4/build/make.log for more information.
and after I reboot with the new kernel (6.5.0-27), Lustre client modules are not available.
The error points to a function called prandom_u32_max which exists in kernel version 5.15, and it seems to be removed in kernel version 6.1. So, it is not possible to build the client module yet on kernel version 6.1+. I do not know about kernel version 6.0.
This work is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.