A Minimum Complete Tutorial of Portable Document Format (PDF) with pdfsh 命令教程
Introduction
PDF is a defacto standard for sharing documents. In this post, I will give a minimal but complete tutorial of Portable Document Format (PDF).
PDF was developed by Adobe beginning in 1993. At its core, it uses PostScript page description language for the description of text and graphics, but it adds many things to PostScript to be able to function as a document format. The main purpose of this post is to explain these additions to PostScript. I will not mention the text and graphics descriptions in this post. If you are looking for anything related to visual representation or rendering of PDF content, this post has nothing related to these topics.
I am going to show the very basics of a PDF file first, and then use pdfsh to show all elements of the PDF file, and the basics of the PDF specification. This post also functions as a tutorial for pdfsh.
The information in this post is based on PDF 2.0 specification, which can be downloaded for free (but it is 1003 pages). PDF 2.0 is also an ISO standard, ISO 32000-2:2020. This is also the reference document for this post. Although I am looking at this latest specification, the core concepts are pretty much the same in previous versions.
The example PDF files I am using are from PDF Association’s PDF 2.0 examples repository. I am particularly using:
In order to show the stream filters: I am using this PDF file: metebalci.com-about.pdf. I created this file by printing the about page of this blog on Windows using Chrome to PDF.
PDF 101
Here are a few basic concepts of Portable Document Format (PDF):
Everything in a
PDF document(here I say document not file on purpose) is anobject. For example, an integer number is an object. An object can be adirect object(used in place without a label, like an integer number 3) or anindirect objectwhich are identified by its identifier (or label), similar to variables in programming languages. An indirect object can be referenced from anywhere in the document. There are nine basic object types in PDF 2.0. I find the categorization in the specification a bit strange, so you can count or categorize the types and reach to a different number. I will show each object type later.The label of an indirect object is composed of two integer numbers. First is the
object number, the other is thegeneration number. The object number is a positive integer (there is no object 0) and it can have maximum 10 digits, thus the maximum value is 9'999'999'999. There is no hard rule to use consecutive object numbers but it simplifies a few things, so it is probably always the case that the first object number is 1 and the next is 2 and so on. The generation number is a non-negative integer, and it has to start from 0 and its maximum value is 65'535. It seems the idea is that there can be different generations (versions) of the same object but practically I believe it is almost always 0, because an object can also be updated and have a different object number. The generation idea sounds unnecessary at the moment, I do not know the historical reason behind it. Although it is 0 most of the time, an object should always be referenced with the object number and generation pair, the object number alone is not enough.A
PDF fileis a binary file having a particular structure, that contains a PDF document, meaning the objects of the PDF document. The PDF file itself, and its first level structures (header, body etc.) are not PDF objects but they help to find and load the actual objects of the PDF document.A PDF file (hence the PDF document) can be incrementally updated.
Incremental updatemeans the file can be modified with existing data left intact. The updates are added only to the end of the file. This means an incremental update can add new objects and modify or delete existing objects. This also means a PDF file may contain objects that are not visible/not used anymore.
When a PDF file is created (meaning it has no incremental updates yet), it has a basic structure consisting of header, body, cross reference table and trailer. Other than the trailer dictionary in trailer (I know this is a bit confusing, trailer is the last part in the file, while trailer dictionary is part of the trailer but trailer contains also something else), the basic structures (header, body etc.) are not objects but stored in the PDF file in a more rigid and fixed structure.
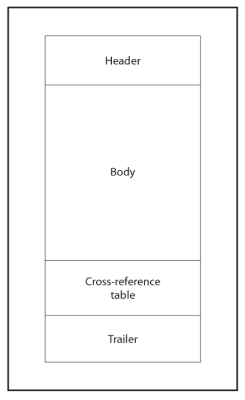
Initial structure of a PDF file (Figure 2 in ISO 32000-2:2020)
The header is only one line and only contains the PDF version.
The body contains all the objects. It is like a linear dump of all objects.
The cross reference table contains the
byte offset(from the start of the file, pointing to a location in the body) of every object of the PDF document. It is basically an (object number, generation number) to byte offset mapping. Remember that even though the concept of generation numbers might not be used, the key of the mapping includes both the object number and the generation number.The trailer contains the trailer dictionary and the byte offset of the start of the cross reference table (also called
startxref) and the trailer dictionary. The trailer dictionary is really aPDF dictionary object.
When a PDF is incrementally updated, a new body, cross reference table and trailer is appended to the end of the PDF file. That means a PDF file in general has one header, and one or more body-xref-trailer groups.
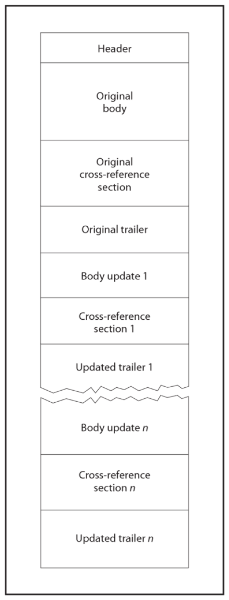
Structure of an updated PDF file (Figure 3 in ISO 32000-2:2020)
It is easy to miss, in Figure 2, xref section is called cross reference table, but in Figure 3, xref sections are called cross reference section. As far as I see, it is not made very clear in the specification, but what I understand is this. The cross reference table is the final structure. A PDF file, updated or not, has only one cross reference table, which makes it possible to find the byte offset of an object (identified by object number and generation number). The cross reference table contains at least one section, but it can contain multiple sections when PDF file is updated. Basically, each update brings another section. From now on, I consistently use cross reference table only to refer to the final data structure.
In order to load the objects (thus the PDF document), after reading the header, the file has to be read from the end, because:
the objects are stored in the body
the location of the objects in the body are stored in the cross reference section
the start of the (last) cross reference section is stored in the trailer at the end of the file
If the PDF file is incrementally updated, the location of previous cross reference section is also stored in the trailer dictionary. Thus, starting from the very end of the document, all trailers and cross reference sections can be read and all objects can be loaded. Since an existing object can be modified or deleted, when reading from the end, the first entry about an object number+generation in a cross reference section is the correct (up-to-date) and valid information, overriding the previous entries.
A cross reference table section does not directly contain all the entries consisting of object number-generation number to byte offset mappings, but first it contains subsections. A cross reference table subsection contains the first object number (of the entries it contain) and one or many entries. Each entry contains a byte offset, generation (number) and deleted mark (or flag). Thus, the entries in a subsection contains information about sequential objects, there is no object number in an entry but it is specified in subsection. This is why it makes sense to use sequential object numbers. Otherwise, many subsections would have to be created.
After all the cross reference sections are read (hence the cross reference table is created), the catalog dictionary, the root page and then all pages and all other objects required to render the PDF document for viewing can be found, loaded and processed.
pdfsh
pdfsh is a utility to investigate the PDF file structure in a shell-like interface, so the structure of the PDF file can be navigated like a file system with commands like ls, cd, cat and a few others.
pdfsh can be installed with pip install pdfsh.
In addition to providing a shell-like interface, pdfsh does one more thing. It implicitly creates a PDF object representation for the header, body, cross reference table sections and the trailer of the PDF file since these are not PDF objects. Thus, in essence, pdfsh is a shell-like interface that has a PDF dictionary object (representing the PDF document) at its root which is the navigation starting from its root.
Running pdfsh Simple\ PDF\ 2.0\ file.pdf gives:
pdfsh Copyright (C) 2024 Mete Balci
License GPLv3+: GNU GPL version 3 or later
Simple PDF 2.0 file.pdf:/ $
pdfsh assumes it is run under a ANSI capable terminal and it uses ANSI terminal features and colors. If strange behavior is observed, make sure the terminal emulation is ANSI compatible.
The $ marks the command line entry and before $ the name of the current PDF file, a colon (:) and the current node is displayed (current node is root, / above).
ESC or ctrl-c can be used to ignore and erase the current command entry. q can be used to quit the pdfsh interface. ? or help shows a brief help screen with valid commands.
%©©F-2.0
It is not directly related to PDF but I have to tell this first.
If your terminal is using UTF-8 encoding (most probably), if a PDF file is used with commands like cat or head in the terminal, the first line is displayed as %©©F-2.0:
$ head -n1 Simple\ PDF\ 2.0\ file.pdf
%©©F-2.0
This is because, the PDF file contains the following in the first line (until the first end of line marker):
$ xxd -l 16 Simple\ PDF\ 2.0\ file.pdf
00000000: 2550 4446 2d32 2e30 0d25 c2a9 c2a9 0d0a %PDF-2.0.%......
It contains %PDF-2.0 but after that there is a carriage return (0d), the percent symbol (25) and two copyright symbols encoded in utf-8 (c2a9) before the actual end of line marker consisting of a carriage return and a line feed (0d0a). Thus, head (or cat), after printing %PDF-2.0, goes back to the beginning of the line (due to carriage return) and overprints %©© and goes to the next line which leaves the line as %©©F-2.0. cat has a show non-printing characters with ^ option (-v) which would result:
$ cat -vE Simple\ PDF\ 2.0\ file.pdf | head -n1
%PDF-2.0^M%M-BM-)M-BM-)^M$
The PDF specification says this is to “ensure proper behaviour of file transfer applications” and when the PDF file contains binary data, the header should be followed by a comment containing four bytes equal or greater than 128 (0x80). I guess c2a9 is selected as a useful option as each byte is >0x80 and it can be printed as © in utf-8 compatible environments.
Since now you know, do not be surprised if you see the copyright symbols or something else instead of %PDF when you try the examples below. For the sake of clarity, I always write %PDF in this post when showing the contents of a PDF file.
Simple PDF 2.0 file
Here is a simple example. In the output below, the objects in the body other than the first one are skipped for clarity. If you have not read the previous section, and wonder why you do not see %PDF-2.0 on your terminal, please read the previous section.
$ cat Simple\ PDF\ 2.0\ file.pdf
%PDF-2.0
1 0 obj
<<
/Type /Catalog
/Metadata 2 0 R
/Pages 3 0 R
>>
endobj
...
<other objects in the body are skipped>
...
% The object cross-reference table. The first entry
% denotes the start of PDF data in this file.
xref
0 10
0000000000 65535 f
0000000016 00000 n
0000000096 00000 n
0000002547 00000 n
0000002619 00000 n
0000002782 00000 n
0000003587 00000 n
0000003811 00000 n
0000003972 00000 n
0000004524 00000 n
trailer
<<
/Size 10
/Root 1 0 R
/ID [ <31c7a8a269e4c59bc3cd7df0dabbf388><31c7a8a269e4c59bc3cd7df0dabbf388> ]
>>
startxref
4851
%%EOF
If you slowly scan the output above, you can see:
the first line is
%PDF-2.0there is a line containing
xrefthere is a line containing
trailerthere is a line containing
startxref
These are the header, the start of the cross reference table section, the start of the trailer and the start of the startxref in the trailer. The body has no start marker. After the header until the start of cross reference table section (xref) it is the body where only the first object (out of nine) is shown above.
Now lets use pdfsh:
$ pdfsh Simple\ PDF\ 2.0\ file.pdf
pdfsh Copyright (C) 2024 Mete Balci
License GPLv3+: GNU GPL version 3 or later
Simple PDF 2.0 file.pdf:/ $
and run ls command:
Simple PDF 2.0 file.pdf:/ $ ls
header/
body/
xrt/
trailer/
objects/
It is not a standard term but in this post and also in pdfsh, I use xrt to refer cross-reference table. This is the final cross-reference table data structure, which is built from the cross-reference table sections in the PDF file.
For convenience, although the document is a dictionary and inherently unordered, the keys of the PDF document dictionary is specially ordered this way to look like a PDF file (header, body, xrt, trailer, …). The keys of all other dictionaries are ordered alphanumerically.
In this post, the pdfsh outputs are always in black and white. However, pdfsh actually uses color. The entries above are shown in blue. pdfsh shows the things that can be entered into (array, dictionary, indirect reference) in blue (this is like a directory in a file system), all others in gray (like a file in a file system).
The type of any object shown in pdfsh can be seen by node command:
Simple PDF 2.0 file.pdf:/ $ node .
. is a dictionary object
. represents the current node (like in a shell). The / node (the document or the PDF file) is a dictionary.
Simple PDF 2.0 file.pdf:/ $ node header
header is a dictionary object
Simple PDF 2.0 file.pdf:/ $ node body
body is an array object
Simple PDF 2.0 file.pdf:/ $ node xrt
xrt is an array object
Simple PDF 2.0 file.pdf:/ $ node trailer
trailer is a dictionary object
pdfsh has auto-completion with tab. node he<TAB> completes into node header/. The final / is because header is a dictionary. It does not matter for node command if it ends with / or not.
header, body, xrt and trailer directly correspond to PDF file structures.
There is only one header in a PDF file, thus header is a dictionary containing the PDF version.
Each incremental update brings a body, and a previous body may still contain an object in use. Thus, body is an array. It is ordered reverse, thus the first (0) element is the body of the last update.
Each incremental update brings a cross reference table section, and a previous cross reference table section may still contain a valid entry. Thus, xrt is an array. Similar to the body, the first (0) element is the cross reference table section of the last update.
Each incremental update brings a trailer. However, only the last trailer dictionary is used for the PDF document. The reason is that it is a must for an update to contain all keys of previous trailer dictionary. Thus, no item of the trailer dictionary can be deleted with an update, they can only be added or modified. The trailer dictionary has a
Prevkey containing the startxref value of the previous update (thus the start of previous cross table section). Thus, the trailer is a dictionary (not an array).
In addition to these nodes, there is also an objects node:
Simple PDF 2.0 file.pdf:/ $ node objects
objects is a dictionary object
The objects node is the final list of objects. If an object is deleted with an incremental update, it is not listed here. If an object is updated with an incremental update, only the last version is listed here. Thus, the PDF document (after the updates are applied) effectively only contains the objects under the objects node. The objects node is naturally not part of a PDF file, this is a virtual construction of pdfsh.
PDF Object Types: Array, Dictionary and Name
Array and Dictionary are the only container object types in PDF. Array is just a list of objects, whereas dictionary gives a mapping from a key to another object. Naturally, an array or a dictonary can also contain other arrays or dictionaries.
pdfsh shows the contents of an array object with indices starting from 0, whereas the contents of a dictionary is shown with the keys, similar to a Python dict.
The key of a PDF dictionary has to be an object of type Name (the key cannot be any other object type). A Name object is just a sequence of characters (a string) but starts with symbol /, such as /Name1. In order to improve readability, pdfsh shows the value of Name objects without /. Thus /Name is displayed as Name. This cannot be confused with regular strings because string objects have delimiters () or <> which you will see later.
An array is represented between the symbols [ and ], whereas a dictionary is represented between the symbols << and >>. Although PDF representations of arrays and dictionaries do not require a separator between the elements (like a comma), pdfsh uses Python syntax to display them and separates the entries with a comma. There are going to be examples of both very soon when we look at the trailer.
Header
The first line of the PDF file is:
$ head -n1 Simple\ PDF\ 2.0\ file.pdf
%PDF-2.0
When using pdfsh, this is stored in the header dictionary with line and version entries.
Simple PDF 2.0 file.pdf:/ $ node header
header is a dictionary object
The contents of a dictonary can be listed by cat:
Simple PDF 2.0 file.pdf:/ $ cat header/
{
line: (%PDF-2.0),
version: 2.0
}
or we can enter into the dictionary with cd (like a directory) and then the keys are listed with ls :
Simple PDF 2.0 file.pdf:/ $ cd header
Simple PDF 2.0 file.pdf:/header $ ls
line
version
where the value of each key can be listed with cat individually:
Simple PDF 2.0 file.pdf:/header $ cat line
(%PDF-2.0)
Simple PDF 2.0 file.pdf:/header $ cat version
2.0
It is also possible to use cat . inside /header.
PDF Object Type: Literal String
The value of line in header is shown between () above. The reason for this is that it is stored (by pdfsh) as a literal string object and PDF literal string objects are enclosed in parentheses ( and ).
Simple PDF 2.0 file.pdf:/header $ node line
line is a literal string object
PDF Version
It might be strange that version is not a string but a name, but it will be clear later why.
Simple PDF 2.0 file.pdf:/header $ node version
version is a name object
The PDF version, when the PDF file is created, is written in the header. However, it is possible to update the version also with Version key in the catalog dictionary. You will see the catalog dictionary later.
Trailer
Just showing the trailer part of the PDF file here again:
trailer
<<
/Size 10
/Root 1 0 R
/ID [ <31c7a8a269e4c59bc3cd7df0dabbf388><31c7a8a269e4c59bc3cd7df0dabbf388> ]
>>
startxref
4851
%%EOF
Just before the very end, there is a line with startxref keyword followed by another line containing an integer number (4851 above). This integer value is the byte offset (from the start of PDF file) of the (last) cross-reference table section.
Going upwards from the startxref keyword, there is the trailer keyword. After the trailer keyword, there is the dictionary between << and >>.
Lets look at the startxref with pdfsh:
Simple PDF 2.0 file.pdf:/ $ node trailer
trailer is a dictionary object
Simple PDF 2.0 file.pdf:/ $ cd trailer
Simple PDF 2.0 file.pdf:/trailer $ ls
dictionary/
startxref
Simple PDF 2.0 file.pdf:/trailer $ node startxref
startxref is a integer object
Simple PDF 2.0 file.pdf:/trailer $ cat startxref
4851
As mentioned before, trailer section and startxref are not objects, but pdfsh represents trailer as a dictionary and stores startxref value as an integer object in this dictionary with startxref key.
The actual trailer dictionary, which is stored as a PDF dictionary object in the PDF file, is also stored in trailer with dictionary key.
Lets look at the trailer dictionary with pdfsh:
Simple PDF 2.0 file.pdf:/trailer $ cat dictionary
{
Size: 10,
Root: (1, 0, R),
ID: [<31c7a8a269e4c59bc3cd7df0dabbf388>, <31c7a8a269e4c59bc3cd7df0dabbf388>]
}
Remember that to improve readability the Name objects are shown without the / in pdfsh. In the trailer dictionary above, for example Size key is actually a Name object /Size.
The value of Size key is an integer (PDF integer numeric object type) representing the number of objects in this document.
The value of ID key is an array (PDF array type), thus it is enclosed between [].
The most important entry in the trailer dictionary is Root. It identifies the Catalog (dictionary) of this document. The catalog dictionary is the root of all document structure, it is how all other information regarding to pages etc. is found.
PDF Object Type: Indirect Reference
The value of Root key above is (1 0 R), which is an indirect reference. It means the catalog (dictionary) object has the object number 1 and the generation 0. R means this is a (indirect object) Reference.
Cross-Reference Table
In order to find and load the catalog dictionary (the object number 1 in the example), and actually before doing anything else, the cross-reference table has to be constructed by reading all cross-reference table sections.
When described like this, it sounds like the trailer dictionary is read after startxref, and it can be read like this. However, I think, it is actually better to think the trailer dictionary is read after the cross reference section is read. This is because in incrementally updated PDF files, the location of previous trailer is not directly known but the location of the start of cross reference section is known. So the previous trailer dictionary can be read after the previous cross reference section is read.
The byte offset of the start of the (last) cross reference section is given by the startxref value (in the trailer), and the section starts with xref keyword.
Each section contains one or more subsections. Each subsection contains a list of entries which are the actual byte-offset values.
Copying the xref part of the file shown before:
xref
0 10
0000000000 65535 f
0000000016 00000 n
0000000096 00000 n
0000002547 00000 n
0000002619 00000 n
0000002782 00000 n
0000003587 00000 n
0000003811 00000 n
0000003972 00000 n
0000004524 00000 n
In the line following xref, a subsection is introduced with two numbers (0 10 above):
- the first number is the first object number in this subsection (0 above)
- the second number is the number of objects in this subsection (10 above)
You might have already realized the Size key of the trailer dictionary also tells the number of objects in cross-reference table, so the second number here (10) is the same as the value of the Size key in the trailer dictionary, because there is only one cross reference table section and subsection in this file.
After these two numbers, there are multiple lines (as much as the number of objects given by the second number when subsection is introduced), with three pieces of information; two numbers and one character.
- the first number (always 10 digits) is the byte-offset of the data of this object in this file (in the second entry above, it is 0000000016=16)
- the second number (always 5 digits) is the generation number for this object (in the second entry above, it is 00000=0)
- a character of
f(meaning free or deleted) orn(meaning in-use) (in the second entry above, it is n)
Because this structure is fixed length, the numbers here are 0 padded. The entries do not specify the object number because the object number is given once for the subsection (0 above) and it is incremented sequentially. So, the first entry is for the object number 0 and the second entry is for the object number 1. The object number 1 is the catalog dictionary referenced from the trailer dictionary as we have seen before.
You might have already realized there is something strange with the first entry. First, its object number is 0, but I said the object number is a positive integer. Second, its generation number is 65535. Last, it is shown free/deleted even though there is no incremental update applied to this file. This is a strange part of the specification. I do not know why it is designed like this, but theoretically, object number 0 is possible as it can be seen in this cross reference table section. However, the object number in an indirect reference has to be a positive integer according to the specification. Then, what is the point of this entry for object number 0 ?
The reason is that the free entries are kept in a free entries list (I believe in order to make it easy to reuse these entries) and there are two ways to keep this list. This is described quite poorly in the specification but the first entry (object number 0) is assumed to be the head of this free entries list, and it should have a generation number 65535.
Body
The body contains the objects in the cross reference section.
Simple PDF 2.0 file.pdf:/ $ node body
body is an array object
Simple PDF 2.0 file.pdf:/ $ cd body/
Simple PDF 2.0 file.pdf:/body $ ls
0/
There is only one, index=0, entry in the body, because this PDF file is not updated.
Simple PDF 2.0 file.pdf:/body $ cd 0/
Simple PDF 2.0 file.pdf:/body/0 $ ls
1.0/
3.0/
4.0/
7.0/
8.0/
9.0/
2.0
5.0
6.0
Just by looking at the ls output, you can see the top 6 are container (dictionary or array) objects (with / suffix). As you might remember the catalog dictionary is (1, 0, R), lets just see what it is:
Simple PDF 2.0 file.pdf:/body/0 $ cat 1.0/
{
Type: Catalog,
Metadata: (2, 0, R),
Pages: (3, 0, R)
}
Before jumping to the document structure and the pages, lets summarize all PDF object types.
PDF Object Types
Lets summarize all the object types:
Boolean:
trueandfalsekeywordsNumeric: Integer (optionally with a sign) or Real (optionally with a sign and decimal point). All numbers are in decimal system and there is no exponent syntax, just plain numbers.
String: Literal or Hexadecimal
Literal string: is written between
(and)such as(This is a string)Hexadecimal string: is written between
<and>such as<65>, this meansb'\x65'in Python syntax
Name: is an atomic symbol, it starts with
/Array: is written between
[and]such as[549 3.14 false (Ralph) /aName]. There is no separator between the elements.Dictionary: is written between
<<and>>such as<</Type Catalog/Version 1>>. The keys of the dictionary is of type Name, hence starts with/. There is no separator between the elements.Null:
nullkeyword
There is also another type (or extended type) of the indirect object which is called stream object.
In the specification, only the object types above and the stream object type is listed and counted, which results 9 object types. It is 9 because integer and real is counted separately but literal and hexadecimal string is counted as one type and there is also stream object. Counting literal and hexadecimal as one type is not too strange, since both are actually byte strings only the representation is different. However, I think, Indirect Reference should also be an object type, because it is also stored in an array or a dictionary.
Indirect Reference and Indirect Object
In the example before, the value of the Root key in the trailer dictionary was (1 0 R). This is an indirect reference.
The indirect object of this indirect reference is at byte offset 16 (as found in the cross reference table entry for object number 1) and it is:
1 0 obj
<<
/Type /Catalog
/Metadata 2 0 R
/Pages 3 0 R
>>
endobj
The indirect object definition starts with object_number generation_number obj line and ends with endobj keyword. The object here is a dictionary with three keys.
Stream Objects
Stream objects are indirect objects with a binary data (bytes). A stream object always has a dictionary (as a direct object) first, and the binary data is stored between stream and endstream keywords, like this:
dictionary
stream
binary data
endstream
Since it has to be an indirect object, in a PDF file it is always found in this form:
N G obj
<< ... >>
stream
binary data
endstream
endobj
The stream dictionary is required to have a key named Length whose value is the number of bytes in the stream.
The binary data inside the stream can be stored as it is, or it can be stored after it is processed (i.e. it can be encoded, compressed and/or encrypted), and this brings the concept of a stream filter. I will explain the stream filters later.
Document structure
PDF represents the document structure in a tree. PDF specification says: “A PDF document can be regarded as a hierarchy of objects contained in the body section of a PDF file”. Until now, I showed how the objects are stored in a PDF file, now these objects will be used to form the document.
The document structure starts from the catalog dictionary which is referenced in the trailer dictionary with the Root key. The catalog dictionary is the root of the document structure tree.
Catalog
As we saw in the trailer dictionary of Simple PDF 2.0 file.pdf before, the catalog dictionary is (1 0) object and it can be viewed with pdfsh easily. All the objects can be found under objects. Remember there can be multiple bodies but objects is the final list of objects.
Simple PDF 2.0 file.pdf:/ $ cat objects/1.0/
{
Type: Catalog,
Metadata: (2, 0, R),
Pages: (3, 0, R)
}
The catalog dictionary must have Type and Pages keys, and the value of the Type key must be Catalog.
The value of the Pages key is an indirect reference to page tree node, and it is 3 0 R above.
Metadata is optional but it is also specified above and it contains an indirect reference to metadata stream.
There are a number of (~30) optional keys that can be used in catalog dictionary.
Page Tree
When a PDF document is viewed, the pages are naturally shown as a linear sequence. However, pages are actually stored in a tree in the PDF document, and a node of this tree is called a page tree node. The pages with a content, thus rendered to the user for display, are the leaf page nodes.
The root of this tree is given by the Pages key in the catalog dictionary, which is 3 0 R above and it is:
Simple PDF 2.0 file.pdf:/ $ cat objects/3.0/
{
Type: Pages,
Kids: [(4, 0, R)],
Count: 1
}
This means, it is a page node with type Pages. This means it is not a leaf node. The Type key is a must in page nodes.
Its kids are given by Kids key and the value is an array.
Count is not the number of kids but the number of leaf page nodes under this node.
Lets look at the kid, the page node (4 0 R):
Simple PDF 2.0 file.pdf:/ $ cat objects/4.0/
{
Type: Page,
Parent: (3, 0, R),
MediaBox: [0, 0, 612, 396],
Contents: [(5, 0, R), (6, 0, R)],
Resources: {
Font: {
F1: (7, 0, R)
}
}
}
It is a page node with type Page, meaning this is a leaf node. Since it is a leaf node, it does not have Kids and Count keys. However, because it is not the root, it has a Parent key. The page tree can have more than 2 levels, hence it is possible to have an intermediate page tree node with type Pages, with a Parent and with Kids.
Other than the Type and Parent, a page would probably contain MediaBox, Contents and Resources at minimum like here. Contents are optional but empty contents mean it is an empty page. MediaBox and Resources are required but they can be omitted and then their value is inherited from the ancestors in the page tree.
The MediaBox defines the boundaries of the page to be displayed or printed as a rectangle in user space units.
The resources required by the content of a page can be given by a dictionary in Resources key. If this key is omitted, it means the resources will be inherited from the ancestors in the page tree. The keys of resources dictionary specifies the type of the resource. There is only one here, the Font type resource and there is only one font resource named F1 which is specified in object (7 0), and it is:
Simple PDF 2.0 file.pdf:/ $ cat objects/7.0/
{
Type: Font,
Subtype: Type1,
BaseFont: Helvetica,
FirstChar: 33,
LastChar: 126,
Widths: (8, 0, R),
FontDescriptor: (9, 0, R)
}
This specifies it is a Type 1 font of Helvetica which is the PostScript language name of the font.
The contents of this page is given in Contents key. Its value can be a stream (an indirect reference to a stream) or an array consisting of indirect references to streams. Above, it is the latter, it is an array. These streams are specifically called as content stream by the specification. If there are multiple streams, they are simply joined when rendering the page. The content streams of this page are objects (5, 0) and (6, 0). Lets see them:
Simple PDF 2.0 file.pdf:/ $ cat objects/5.0/
{
Length: 746
}
Since this is a stream, only the stream dictionary is shown by cat command with pdfsh. The contents (stream data) can be viewed by cats or catsx. cats decodes the stream data with utf-8 encoding and displays it as text, which would work here. Otherwise, catsx displays the content as hexadecimal string.
The content stream contains PostScript instructions, hence it will not make much sense to many but this one has comments, here it is:
Simple PDF 2.0 file.pdf:/ $ cats objects/5.0/
% Save the current graphic state
q
% Draw a black line segment, using the default line width.
150 250 m
150 350 l
S
% Draw a thicker, dashed line segment.
4 w % Set line width to 4 points
[4 6] 0 d % Set dash pattern to 4 units on, 6 units off
150 250 m
400 250 l
S
[] 0 d % Reset dash pattern to a solid line
1 w % Reset line width to 1 unit
% Draw a rectangle with a 1-unit red border, filled with light blue.
1.0 0.0 0.0 RG % Red for stroke color
0.5 0.75 1.0 rg % Light blue for fill color
200 300 50 75 re
B
% Draw a curve filled with gray and with a colored border.
0.5 0.1 0.2 RG
0.7 g
300 300 m
300 400 400 400 400 300 c
b
% Restore the graphic state to what it was at the beginning of this stream
Q
This content stream draws a black solid line, a black dashed line, a rectangle and a filled curve. The other content stream is very short:
Simple PDF 2.0 file.pdf:/ $ cats objects/6.0/
% A text block that shows "Hello World"
% No color is set, so this defaults to black in DeviceGray colorspace
BT
/F1 24 Tf
100 100 Td
(Hello World) Tj
ET
This content stream only draws a text block to show “Hello World”.
The PDF file with these two content streams looks like this:
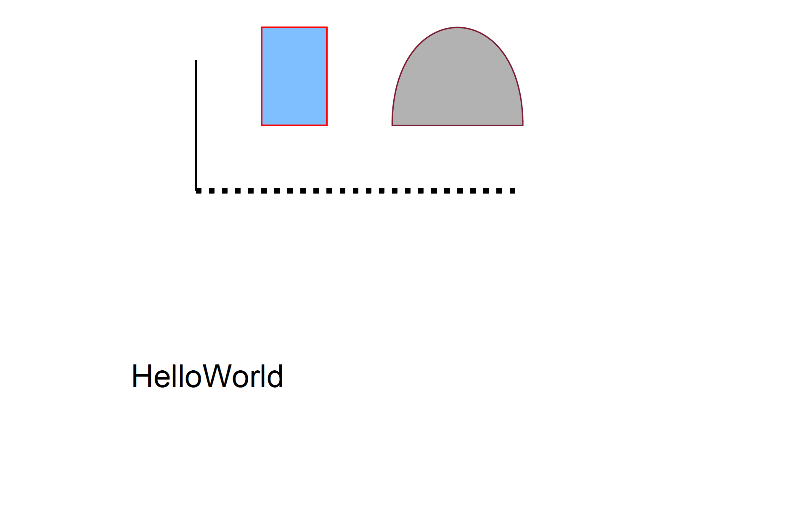
Simple PDF 2.0 file.pdf
Incremental Updates
There are some rules on how incremental updates should function:
The updated trailer dictionary always include all the information of the previous trailer dictionary. The value of a key naturally can be updated but it includes all of them even if it is not updated. So the last trailer dictionary contains all the information. This is why it is called updated trailer.
The
IDkey in trailer dictionary contains an array with two byte strings. These byte strings are unique (generated from the hash of the file etc.). When the PDF file is created, both strings contain the same value. When it is updated, the second is updated.An updated trailer, in addition to the keys of the previous trailer, includes a key named
Prev, which points to the byte offset of the start of previous cross-reference table section (or in other words, it contains the value ofstartxrefbefore the update).
PDF 2.0 via incremental save
Now lets look at the second example, PDF 2.0 via incremental save.pdf.
$ pdfsh PDF\ 2.0\ via\ incremental\ save.pdf
pdfsh Copyright (C) 2024 Mete Balci
License GPLv3+: GNU GPL version 3 or later
PDF 2.0 via incremental save.pdf:/ $ cat header/
{
line: (%PDF-1.7),
version: 1.7
}
The first interesting thing is the PDF version in the header (thus, when the PDF file is created) is 1.7 not 2.0.
PDF 2.0 via incremental save.pdf:/ $ ls body/
0/
1/
The body has two elements, thus, it is updated once. The new or modified objects are (meaning these are the objects in the last body section):
PDF 2.0 via incremental save.pdf:/ $ ls body/0/
1.0/
9.0/
6.0
The original objects are:
PDF 2.0 via incremental save.pdf:/ $ ls body/1/
1.0/
3.0/
4.0/
7.0/
8.0/
9.0/
2.0
6.0
The final objects are:
PDF 2.0 via incremental save.pdf:/ $ ls objects/
1.0/
3.0/
4.0/
7.0/
8.0/
9.0/
2.0
6.0
Thus, it looks like, the object number 1, 9 and 6 is updated, and no object is deleted. If, for example, the object 9 was deleted, it would not be listed under objects.
Lets look at the trailer:
PDF 2.0 via incremental save.pdf:/ $ cat trailer/
{
dictionary: {
Size: 10,
Root: (1, 0, R),
Prev: 4287,
ID: [<15d2e6da9695e5fc3c609cbb33346129>, <31c7a8a269e4c59bc3cd7df0dabbf388>]
},
startxref: 5342,
prev: {
dictionary: {
Size: 10,
Root: (1, 0, R),
ID: [<15d2e6da9695e5fc3c609cbb33346129>, <15d2e6da9695e5fc3c609cbb33346129>]
},
startxref: 4287
}
}
As before, there is a dictionary and startxref keys of the trailer but there is also prev key. The trailer dictionary (the value of dictionary) is similar but it has a Prev key with value 4287. Also the second element of the array at ID key is different. These are all as expected.
pdfsh adds the previous trailer to the trailer as prev key (not Prev). As expected, the elements of its ID array has the same values and its startxref is different.
Finally, if we check the catalog dictionary (the value of the Root key in catalog dictionary):
$ cat objects/1.0/
{
Type: Catalog,
Pages: (3, 0, R),
Metadata: (2, 0, R),
Version: 2.0
}
It has a Version key with the value 2.0. This came with the update, because the previous object has no such key:
PDF 2.0 via incremental save.pdf:/ $ cat body/1/1.0/
{
Type: Catalog,
Metadata: (2, 0, R),
Pages: (3, 0, R)
}
It might not be clear, it also surprised me, the version is not a string.
PDF 2.0 via incremental save.pdf:/ $ node objects/1.0/Version
Version is a name object
It is a Name object. That is why I also decided to represent the version in the header as a Name object not as string.
Stream Filters
I have mentioned before that the stream data can be pre-processed. This is done with stream filters. A stream filter can theoretically be anything taking a binary data as input and producing a binary data as output. In PDF, it is used for encoding (such as ASCII 85 for text or DCT for images), compression (such as LZW) or encryption. Also, multiple filters can be used, one after other. The filters used for a data in a stream is given in Filter key of the stream dictionary. The filters defined in PDF 2.0 spec are:
- ASCII Hex: encoded in an ASCII hexadecimal representation
- ASCII 85: encoded in an ASCII base-85 representation
- LZW*: compressed using the LZW adaptive compression method
- Flate (deflate)*: compressed using the zlib/deflate compression method
- Run Length: compressed using a byte-oriented run-length encoding algorithm
- CCITT Fax*: compressed using the CCITT facsimile standard (Group 3 or Group 4)
- JBIG2*: compressed using the JBIG2 standard (excluding color palette coding)
- DCT*: compressed using a DCT (discrete cosine transform) based on JPEG standard
- JPX: compressed using the wavelet-based JPEG 2000 standard
- Crypt*: encrypted (exact mechanism is given in parameters, RC4, AES-128 CBC or AES-256 CBC)
The ones marked with an * above have parameters, which are stored in the stream dictionary with DecodeParms key.
When the data in a stream is read, and it has a filter (or filters), the reverse of the filter (or filters) has to be applied to derive the actual data, i.e. if it is encoded, the data has to be decoded first.
The PDF files shown before have no stream filters, so I have another example.
metebalci.com-about.pdf
Lets see what this PDF has:
metebalci.com-about.pdf:/ $ cat trailer/
{
dictionary: {
Size: 149,
Root: (136, 0, R),
Info: (1, 0, R)
},
startxref: 101850
}
Lets look at the catalog (136, 0):
metebalci.com-about.pdf:/ $ cat objects/136.0/
{
Type: Catalog,
Pages: (28, 0, R),
MarkInfo: {
Type: MarkInfo,
Marked: True
},
StructTreeRoot: (29, 0, R),
ViewerPreferences: {
Type: ViewerPreferences,
DisplayDocTitle: True
},
Lang: (en-us)
}
Lets look at the page tree root (28, 0):
metebalci.com-about.pdf:/ $ cat objects/28.0/
{
Type: Pages,
Count: 2,
Kids: [(2, 0, R), (23, 0, R)]
}
Lets look at the first kid (2, 0):
metebalci.com-about.pdf:/ $ cat objects/2.0
{
Type: Page,
Resources: {
ProcSet: [PDF, Text, ImageB, ImageC, ImageI],
ExtGState: {
G3: (3, 0, R)
},
Font: {
F4: (4, 0, R),
F5: (5, 0, R),
F6: (6, 0, R)
}
},
MediaBox: [0, 0, 594.96, 841.92],
Annots: [(7, 0, R), (8, 0, R), (9, 0, R), (10, 0, R), (11, 0, R), (12, 0, R), (13, 0, R), (14, 0, R), (15, 0, R), (16, 0, R), (17, 0, R), (18, 0, R), (19, 0, R), (20, 0, R), (21, 0, R)],
Contents: (22, 0, R),
StructParents: 0,
Parent: (28, 0, R)
}
Lets look at the contents of this kid (22, 0):
metebalci.com-about.pdf:/ $ cat objects/22.0
{
Filter: FlateDecode,
Length: 3516
}
This is a stream dictionary and it specifies FlateDecode filter. It is difficult to see the effect of this without extracting the data. A powerful and useful feature of pdfsh is that it can extract both encoded and decoded data from a PDF stream, using catsb.encoded and catsb.decoded commands. These are used directly from the OS command line with -c option and output is written to stdout. These commands cannot be used in the pdfsh shell interface.
$ pdfsh -c 'catsb.encoded objects/22.0' metebalci.com-about.pdf | wc -c
3516
$ pdfsh -c 'catsb.decoded objects/22.0' metebalci.com-about.pdf | wc -c
20732
So the compressed content is 3516 bytes and uncompressed is 20732. Lets look at the first 100 bytes of original (encoded) content (data of the stream):
$ pdfsh -c 'catsb.encoded objects/22.0' metebalci.com-about.pdf | xxd -l 100
00000000: 789c e55c 5b8b 5c39 0e7e af5f 719e 17d6 x..\[.\9.~._q...
00000010: b16c c917 0881 ba74 857d 18d8 1902 f303 .l.....t.}......
00000020: 6677 322c 9d81 c9fe 7f58 ece3 8bec 73ec fw2,.....X....s.
00000030: aaca a47b 7bd9 4093 6a9f 3ab2 24cb d227 ...{{.@.j.:.$..'
00000040: 596e a1b4 8fff 16b9 c8e5 af82 fdea 1084 Yn..............
00000050: 07ef ddf2 cb97 c31f 0700 1246 d192 ff57 ...........F...W
00000060: 0a8d 7096 ..p.
and the decoded content:
$ pdfsh -c 'catsb.decoded objects/22.0' metebalci.com-about.pdf | xxd -l 100
00000000: 2e32 3339 3939 3939 3920 3020 3020 2d2e .23999999 0 0 -.
00000010: 3233 3939 3939 3939 2030 2038 3431 2e39 23999999 0 841.9
00000020: 3139 3938 2063 6d0a 710a 3131 352e 3632 1998 cm.q.115.62
00000030: 3520 3131 352e 3632 3520 3232 3436 2e38 5 115.625 2246.8
00000040: 3735 2033 3237 3520 7265 0a57 2a20 6e0a 75 3275 re.W* n.
00000050: 710a 332e 3132 3520 3020 3020 332e 3132 q.3.125 0 0 3.12
00000060: 3520 3131 5 11
The original encoded data, as expected, is not readable/understandable but the decoded data is clearly readable.
The data of any stream object can be extracted from a PDF file using pdfsh as long as the filters are supported by pdfsh.
This work is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.